
Tesseract OCR을 처음 학습시킬 때 정보가 충분하지 않아 오랜시간 헤맸던 기억이 있다.
방법을 찾아 학습시켜본 지는 꽤 오래됐지만 누군가에게 도움이 되지 않을까 해서 방법을 글로 정리해보려고 한다.
Tesseract OCR 엔진에 대해서는 이전 글에서 정리해두었다.
https://wandukong.tistory.com/6
Tesseract OCR
이번 포스팅에서는 OCR 하면 빼놓을 수 없는.. 역사 깊은 Tesseract OCR 엔진에 대해 다뤄보겠다. 내가 오랜 기간 사용하면서 정리하고 기록한 내용을 적어보려한다. 먼저 이번 포스팅에서는 Tesseract O
wandukong.tistory.com
Tesseract OCR의 버전은 크게 세가지가 있다.
Tesseract Version
- Tesseract 3.X (legacy)
- Tesseract 4.X (+ LSTM) : Line Detection, Fine Tuning
- Tesseract 5.X (+ For Windows) : by UB Mannheim
그 중에서도 Windows에서도 사용할 수 있는 Tesseract 5.X 을 학습시키는 방법에 대해 설명하겠다.
모든 방법은 Tesseract 공식문서 https://tesseract-ocr.github.io/tessdoc/ 와 Tesseract 5.0 내의 문서를 참고했다.
+)
사실 Tesseract 4.X 으로 먼저 학습시키려고 했었다.
윈도우에서 cygwin을 사용하면 될 거라고 공식문서에 적혀있었지만 윈도우에서는 특정 단계에서부터는 진행이 되지 않는다.. (tesstrain.sh 의 text2image가 windows에선 돌아가지 않았다ㅜㅜ 현재는 어떨지 모르겠다)
[Tesseract OCR 5.0 학습 방법]
1. Tesseract OCR 5.X 버전 다운로드
https://github.com/UB-Mannheim/tesseract/wiki 이 사이트에서 설치

📌 + 22/08/03 )
최근 Tesseract OCR 5가 업데이트 되면서 설치했을 때 기본으로 들어있는 모델이 학습이 불가능한 모델로 바뀐 것 같습니다.
[해결 방법1]
당시 제가 사용했던 버전은 위 사진에 나와있는 것처럼 20210811 버전이므로, 해당 페이지에서 old versions에 들어가 같은 버전(~20210811.exe) 을 다운받아 사용하시면 됩니다.
[해결 방법2]
https://github.com/tesseract-ocr/tessdata_best 에서 사용할 best traineddata를 다운받아 기존에 들어있는 trainneddata 대신 사용해주시면 됩니다.
2. 학습 데이터 준비
다운받은 Tesseract-OCR 폴더에 .box 파일과 .tif(.tiff) 파일을 준비한다.

위 사진의 .box 파일(텍스트)과 .tiff 파일(이미지)로 .lstmf 파일을 만들어야 한다.
.box의 포맷은 여러가지가 있는데 아래 링크를 참고해서 만들면 되고
이 글은 'lstmbox' 포맷 을 사용한 내용으로 작성했다.
https://github.com/tesseract-ocr/tesseract/issues/2357
.box 파일명과 .tif 파일명은 위 사진의 파일명처럼
{LANG_CODE}.{fontname}.{EXP}.box/tif 형식으로 설정해준다.


3. lstmf 파일 만들기
tesseracr.exe가 위치해 있는 Tesseract-OCR 폴더에서
아래 명령어를 각자 파일명에 맞게 수정 후 실행하면 lstmf 파일이 생성된다.
tesseract eng.font.HalfTextData0.tif eng.font.HalfTextData0 -l eng --psm 6 lstm.train
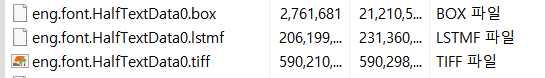
4. lstm 파일 만들기
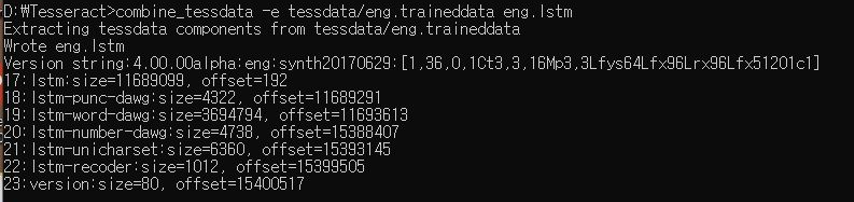
기존 eng.traineddata로 부터 eng.lstm 파일을 만듦
combine_tessdata -e tesseract/tessdata/eng.traineddata eng.lstm
5. 학습 진행
아래 명령어를 실행하면 학습이 진행 된다.
--max_iterations를 점점 높여 계속 아래 명령어를 실행하면 된다.
더이상 성능이 좋아지지 않을 때 중단하면 된다.
-- debug_interval -1로 설정하면 모든 iteration동안의 debugging 정보를 확인할 수 있고
-- debug_interval 0으로 설정하면 뜨지 않는다.
lstmtraining \
--model_output {결과를 저장할 path}\
--continue_from {lstm 파일의 path}\
--train_listfile {lstmf 파일의path}\
--traineddata tesseract/tessdata/eng.traineddata\
--debug_interval -1
--max_iterations 400
설정한 iteration만큼 학습이 완료되면, 아래 사진과 같이 error rate를 포함한 각종 결과들이 출력된다.
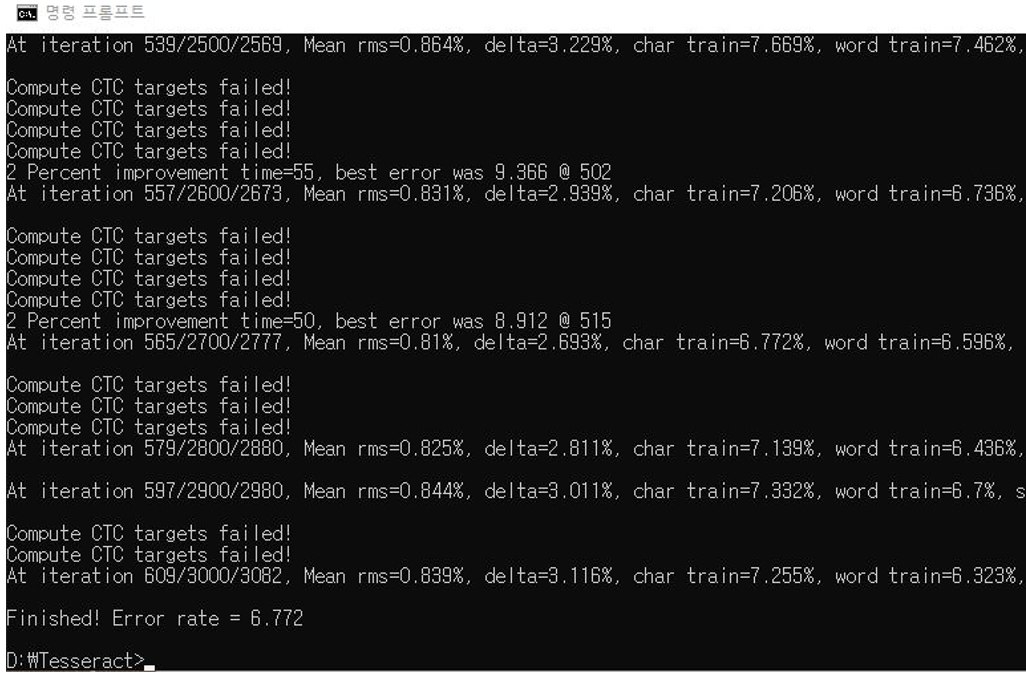
처음엔 max_iteration을 늘려 학습시킬 수록 error rate이 잘 줄어드는데 어느 순간부터는 error rate이 줄지 않을 것이다.
더 이상은 학습을 진행해도 의미가 없으므로 이때 아래 방법으로 그동안 학습한 weight를 저장하여 중단하면 된다.
6. 학습 중단
학습이 잘 되었다면 Tesseract-OCR 폴더에 아래와 같은 .checkpoint 파일들이 생겼을 것이다.

앞에 표시한 숫자는 error rate이고 뒤에 표시한 숫자는 iteration이다.
checkpoint 파일들 중에 최종 traineddata로 만들고 싶은 파일을 선택해 둔다. (error rate이 작은 걸 선택하면 됨)
아래 명령어를 수정하여 실행한다.
lstmtraining --stop_training\
--continue_from .\{선택해둔 checkpoint 파일명}.checkpoint\
--traineddata tessdata/eng.traineddata\
--model_output {새로운 traineddata명}.traineddata
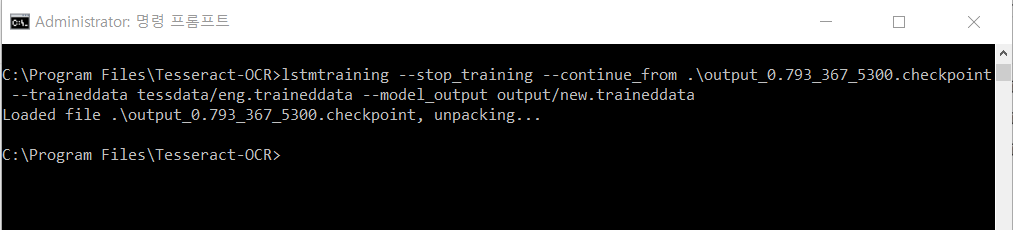
여기까지 잘 진행되었다면, --model_output에서 설정한 경로에 지금까지 학습시킨 traineddata파일이 저장되어 있다.

여기까지 왔다면 학습 성공이다 🥳🥳
이렇게 만든 traineddata로 Tesseract OCR을 실행하려면 parameter에 해당 파일을 지정하여 사용하면 된다.
다음에 기회가 되면 파이썬으로 Tesseract OCR을 사용하는 방법도 간단하게 다뤄보려고 한다.
- 학습한 모델로 pytesseract 사용방법 : https://wandukong.tistory.com/9
pytesseract 사용방법
요새 tesseract5 학습 방법을 보고 찾아오시는 분이 많길래 학습한 모델을 사용하는 방법도 알려드리면 좋을 것 같아 포스팅해봅니다! windows용 tesseract 5.0 학습방법 : https://wandukong.tistory.com/7 Tes..
wandukong.tistory.com
'머신러닝 > OCR' 카테고리의 다른 글
| EasyOCR 사용 방법 (7) | 2022.01.16 |
|---|---|
| pytesseract 사용방법 (0) | 2021.11.04 |
| EasyOCR 소개 (0) | 2021.10.10 |
| Tesseract OCR (0) | 2021.05.08 |
| GOCR (0) | 2021.04.02 |



