이번 포스팅에서는 OCR 하면 빼놓을 수 없는.. 역사 깊은 Tesseract OCR 엔진에 대해 다뤄보겠다.
내가 오랜 기간 사용하면서 정리하고 기록한 내용을 적어보려한다.
먼저 이번 포스팅에서는 Tesseract OCR에 대한 간단한 소개와 Tesseract에서 OCR이 어떻게 이루어지는지를 정리해보겠다.

참고, 이미지 출처)
- overview논문 : storage.googleapis.com/pub-tools-public-publication-data/pdf/33418.pdf
- main repository : github.com/tesseract-ocr/tesseract
tesseract-ocr/tesseract
Tesseract Open Source OCR Engine (main repository) - tesseract-ocr/tesseract
github.com
History
- Tesseract는1984~1994년에 처음 HP에 의해 개발됨
- HP의 독자적인 페이지 레이아웃 분석 기술을 이용함
- 2005년에 처음 오픈소스로 배포됨
전체적인 OCR 과정
1. Connected component analysis를 통해 Blob단위로 검출
2. Blob들을 text line에 매칭시킴
- Fixed pitch text는 바로 character cell로 쪼갬
- Proportional text는 단어로 쪼갬

3. 두 가지 과정으로 인식 수행
- 단어 인식(adaptive classifier를 거침-> training data로 작용)
- 페이지 윗 부분부터 다시 인식함 (page 아래에 와서야 adaptive classifier가 제대로 동작할 거니까)
Line & Word Finding
(1) Line Finding
Line Finding의 핵심은 1. Blob Filtering 2. Line Construction 두 가지
- 기울어진 페이지(skewed page)를 재조정하지 않고 인식하게 함
- 페이지 레이아웃 분석 후, roughly uniformed 텍스트 사이즈로 text region이 나눠진 상태
- 각 Text Region에서 text height의 중간값을 정해서 작은 blob들을 걸러냄
- Blob을 Textline에 할당함. ( 걸러진 Blob도 적절한 Line에 할당)
- 마지막으로 Blob들을 merge해서 Line Finding을 끝냄 + base line fitting

(2) Fixed Pitch Detection & chopping
- Text line이 fixed pitch인지 아닌지 확인
- Fixed pitch이면 pitch를 이용해 character 단위로 쪼개고, 여기에 대해서는 word recognition step을 수행하지 않게 함
(3) Proportional Word Finding
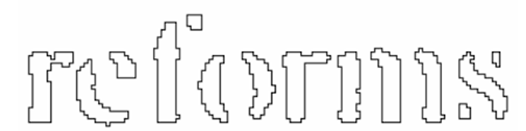
- Fixed Pitch가 아닌 word의 경우
- Proportional text의 경우 word 영역을 구분하기가 어려운 경우가 있음 -> fuzzy space로 만듦
- fuzzy space의 인식은 word 인식 후에 이루어짐


논문에서 word 영역 구분이 어려운 이유로 두 가지 예시를 들었는데,
첫번째는 kerned space가 서로 다름을, 두번째는 horizontal gap이 차이가 나지 않음을 이야기 했다.
(kerning의 뜻을 찾아보니 글자간 간격을 조정하는 것을 의미하는 듯하다.)
위 사진에서 1 을 보면 'erated'와 '11.9%' 의 kerned space가 다른 것을 확인할 수 있다.
또 2 를 보면 'of'의 'f'와 'financial'의 'f'간 horizontal gap이 없는 것을 확인할 수 있다.
Word Recognition
Word Recognition : 단어를 어떻게 character로 쪼개는지가 핵심
- Line Finding 결과로 먼저 분류
- 남아있는 Proportional word는 다른 word recognition 방법으로 분류
(1) Chopping joined characters
- Polygonal approximation of outline으로 오목한 점(Concave vertices)를 찾음 -> "Candidate chop points"
- 우선순위에 따라 쪼개고 confidence를 향상시키지 못한 chop은 취소됨
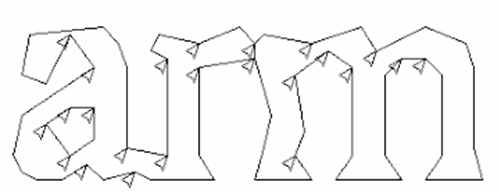
(2) Chopping joined characters
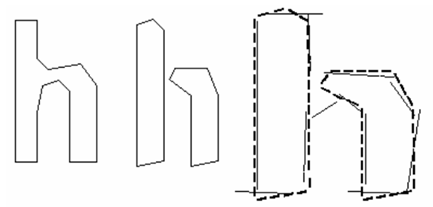
- chop 후에도 단어 인식이 잘 안되면 Associator가 처리함
- Blob을 가장 잘게 쪼갰을 때 가능한 조합으로 segmentation graph를 만들어서 검색함

-> "Fully-chop-then-associate 방식"
- 장점)
- 자료구조를 simplify할 수 있음
- broken character를 인식 가능
- 단점)
- 비효율적일 수 있음
- 중요한 부분을 chop해서 놓칠 가능성이 있음
Feature
- topology feature를 사용하는 방식 -> real life image에 적합하지 않음
- Polygonal approximation features를 사용하는 방식 -> damaged character에 적합하지 않음
- 작은 Feature를 큰 prototype에 매치시키는 방법 (-> 대신 computational cost는 큼)

Training Data
- Classifier가 damaged character를 잘 인식해서 학습데이터로 사용하지 않아도 되었다고 함
- 다른 classifer들에 비해 훨씬 적은 양의 training sample로 학습시키는 게 가능했음
+ 참고)
- (94개의 문자를 20개의 샘플로만 학습) * (8개의 폰트) * normal/bold/italic/bold italic 4가지 특성
-> 94 * 8 * 4 = 60160개
Tesseract Version
- Tesseract 3.X (legacy)
- Tesseract 4.X (+ LSTM) : Line Detection, Fine Tuning
- Tesseract 5.X (+ For Windows) : by UB Mannheim
다음엔 Tesseract 5.X 사용방법과 학습시키는 방법에 대해 포스팅 하겠습니다
'머신러닝 > OCR' 카테고리의 다른 글
| EasyOCR 사용 방법 (7) | 2022.01.16 |
|---|---|
| pytesseract 사용방법 (0) | 2021.11.04 |
| EasyOCR 소개 (0) | 2021.10.10 |
| Tesseract OCR 5.0 Windows용 학습 방법 (24) | 2021.08.26 |
| GOCR (0) | 2021.04.02 |



