human pose estimation에 대한 리뷰 논문의 리뷰(?)입니다.
저는 human pose estimation 중에서도 딥러닝을 이용한 body pose estimation에 관심이 있습니다.
따라서 body 위주의 내용을 다루려고 합니다.
논문 링크 : https://arxiv.org/abs/2110.06877
A Review on Human Pose Estimation
The phenomenon of Human Pose Estimation (HPE) is a problem that has been explored over the years, particularly in computer vision. But what exactly is it? To answer this, the concept of a pose must first be understood. Pose can be defined as the arrangemen
arxiv.org
1. Introduction to Human Pose Estimation (HPE)

Pose란?
사람의 관절을 특정 방식으로 배치한 것
-> 따라서 HPE는 이미지나 영상에서 사람의 관절이나 미리 정의된 랜드마크의 localization 문제라고 볼 수 있음
Human Pose Estimation는 여러가지 종류가 있음
- body
- face
- hand
2. Deep learning in HPE and What was done before
(1) Classical Approaches to HPE

Pictorial Structures Model
body part를 spatial correlation으로 모델링함
- 트리구조의 그래프 모델로 표현
- 관절의 위치를 예측하기 위함
- spatial connection은 스프링을 이용해 표현됨
[문제점]
- 보이지 않는 신체 일부 간 상관 관계를 알 수가 없는 문제가 있음
- 즉, 사람의 팔 다리가 보이지 않으면 에러를 보이는 경향이 있음
Flexible Mixture-of Parts ( FMP)
템플릿을 사용해 보이지 않는 신체를 매칭함
- 각 모델은 global, part templates이 있음
- 작고 방향이 없는 부분의 조합으로 만듦
- viewpoint에 따라 limb가 어떻게 보이고 변하는지를 확인할 수 있음
- dp를 사용해 similar warp 간 계산을 빠르고 효율적으로 함
(2) Deep Learning in Convolutional Pose Machine
Convolutional Pose Machine (CPM)

- 최초의 딥러닝 기반 pose estimation 모델
- multi class predictor 각 계층에서 각 part의 location을 예측하도록 학습된 multi class predictor
- sequential prediction 프레임워크는 이전 단계의 belief map에 대해 더 큰 receptive field를 사용함
- vanishing gradient 문제는 각 단계 직후 supervision으로 해결함
- CPM 의 첫번째 단계에서 7층의 CNN을 사용한 local image evidence 만을 이용해 part belief를 예측함
- 위 단계로부터의 belief map은 input data에 추가됨
- 이후 단계에서는 effective receptive field가 정확도를 높임
-> 그래프 모델로의 추론 없이도 image feature와 image dependent spatial model을 학습할 수 있게 함
3. Accuracy and Metrics
(1) Definition of Accuracy and Concept of Metrics
HPE 성능을 평가할 때 고려해야할 것들이 다양하기 때문에 다양한 평가 지표가 존재함
(2) Different Metrics Used in HPE
Intersection Over Union (IOU)
- GT와 predicted bounding box 간 차이 계산
- 보통 0.5 이하면 없앰
Percentage of Correct Parts (PCP) and Percentage of Detected Joints(PDJ)
PCP
- 요즘은 잘 쓰이진 않음
- limb에 대한 localization accuracy을 계산하기 위함
- predicted joint 와 GT joint 사이의 거리가 limb length의 특정 비율보다 작은지 판단
- 높은 PCP measure는 높은 성능을 의미함
- short length의 limb 에서 정확하지 않기 때문에 PDJ가 만들어짐
PDJ
- PCP와 같은 logic
- torso diameter를 이용함
- threshold에 대한 모든 관절을 결정하는 accuracy를 의미함
+ torso diameter)
The torso diameter is defined as the distance between left shoulder and right hip of each ground-truth pose
Percentage of Correct Keypoints (PCK)
- 특정 threshold 내의 다양한 keypoint의 localization accuracy를 측정하기 위함
- 머리 길이의 50%로 설정됨
- PCK 값이 클수록 좋은 성능을 의미함
Average Precistion (AP)
total positive result에 대한 TP 비율 (TP/ (TP +FP))
모든 recall value에 대한 precision 평균
- Mean Average Precision (MAP)
- 모든 class의 평균 precision에 대한 평균
Average Recall (AR)
GT positive에 대한 TP 비율
모든 recall value에 대한 recall 평균
- Mean Average Recall(MAR)
- 모든 class의 평균 recall에 대한 평균
Object Keypoint Similarity (OKS)
- 모든 object keypoint 간 평균 keypoint similarity
- subject의 scale과 gt와 predticted keypoint 간 거리에 따라 계산함
- AP, AR을 계산하는데 도움이 됨
Mean Per Joint Error (MPJPE)
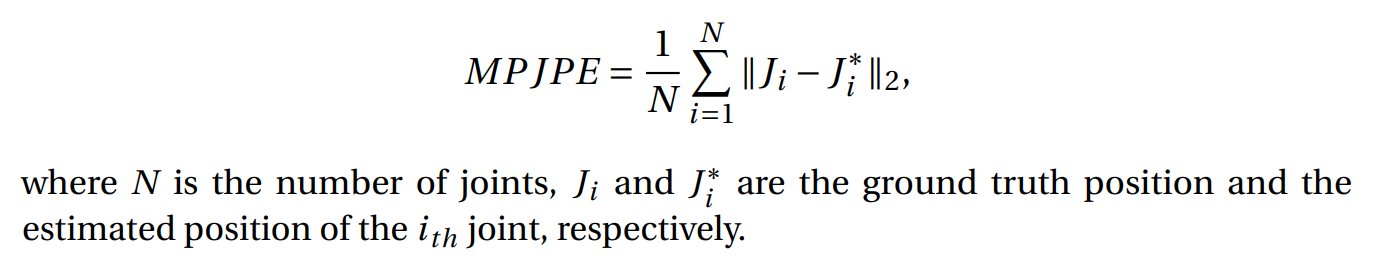
- 3D HPE에서 가장 많이 쓰이는 지표
- 측정된 3D joint와 gt position 간 Euclidean Distance를 계산함
4. Standards and Categorization for HPE
(1) Table of Standards
HPE에서 Standard는 landmark의 개수를 의미함 (localize되어야 하는 관절의 수나 미리 정의된 landmark)
이 개수는 방법에 따라 다양하게 정의됨

face의 경우 대부분 68개의 landmark 사용 (실험적으로 68개 이외에는 성공적이지 못했음)
단 MediaPipe Face Mesh의 경우 468개 이기도 함
마찬가지로 hand의 경우에도 대부분 21개 사용 (마찬가지로 21개 이외에는 성공적이지 못했음)

(2) Categorization for HPE
HPE에서 categorization은 해상도와 landmark의 개수로 정할 수 있음
First Category : low resolution with up to 30 landmarks
- 매칭해야 할 landmark가 많지 않다면, 낮은 해상도로도 충분함
- 20개의 landmark 정도로 적은 body estimation에 주로 해당됨
- + occlusion과 complex pose의 문제는 큰 receptive field로 해결할 수 있으므로 높은 해상도가 필요하지 않음
Second Category : high resolution for dense poses
- 30개 이상의 landmark의 경우, 정확한 localization을 위해 높은 해상도가 필요함
- face와 hand estimation이 해당됨
5. Datasets used in HPE
논문에서는 Body, Face, Hand로 나누어 설명하고 있지만,
관심이 있는 Body pose estimation를 집중적으로 소개하겠습니다.
(1) Body Datasets
COCO
- multi-person 2D body dataset으로 가장 많이 쓰임
- 200k의 17개 까지의 keypoint가 라벨링 된 people 이미지
- HPE를 위한 두 가지 버전이 있음
- 2016 / 2017 COCO keypoints
- train/val/test의 분리 여부 차이
MPII
- single person 2D body dataset
- 16개 까지의 joint가 annotation된 40k명의 사람을 포함한 25k개의 이미지
- 410개의 라벨링 된 human activity도 있음
- YouTube 영상에서 얻음
- + body part occlusion, 3D torso, head orientation 같은 advanced annotation도 라벨링 되어있음
- 2014년에 만들어짐
AI Challenger Human keypoint Detection
- 2D body dataset
- 2D 중 가장 큰 dataset
- 14개의 keypoint가 annotation 되어있는 300k개의 고화질 이미지
- 600k개의 testing 이미지
- internet search engine에서 얻음
- MPII와 유사하게, 다양한 자세의 daily activity에 대한 dataset
- + zero-shot recognition 기반의 attribute가 있고 chinese captioning이 있음
- 2017년에 만들어짐
PoseTrack
- multi-person 2D video based body dataset
- 약 1356개의 video sequence, 46k개의 annotated frame, 276k개의 body pose annotation
- 사람마다 unique track ID를 제공함
- 15개의 keypoint
- 2017년에 만들어짐
Human3.6M
- 3D body dataset
- 가장 유명하고 가장 큰 indoor dataset
- 11명의 전문 배우가 17 가지의 행동을 4가지 view에서 수행
- 24개의 keypoint
(2) Face Datasets
- 300W
- AFLW
- MERL-RAV
- COFW
- WFLW
(3) Hand Datatsets
- BigHand2.2M
- GANerated Hand Dataset
- NYU Hand Dataset
- HandNet Dataset
(4) Whole Body Datasets
- COCO-WholeBody
6. 2D vs 3D HPE
이 장에서는 2D, 3D 별 face, hand, body 논문과 github 레포지토리를 표로 정리해놓았습니다.
논문을 참고하시면 좋을 것 같습니다.
7. Pose Estimation on Images and Videos
이 장에서는 input이 single image인 경우, video인 경우의 논문과 github 레포지토리를 표로 정리해놓았습니다.
마찬가지로 논문을 참고하시면 좋을 것 같습니다.
리뷰 논문을 통해서 pose estimation의 전반적인 내용을 살펴보았습니다.
관심있는 분야인 body pose estimation을 중심으로 읽어보았는데요, 저는 그 중에서도 흥미가 있는 video 기반의 연구에 대해 좀 더 알아보려고 합니다. 😊
'머신러닝 > Human Action Recognition' 카테고리의 다른 글
| [논문 리뷰] Human Action Recognition and Prediction: A Survey (2) (0) | 2021.03.27 |
|---|---|
| [논문 리뷰] Human Action Recognition and Prediction: A Survey (1) (0) | 2021.03.25 |

